270
270

Не минуло й двох років, як ChatGPT від OpenAI був випущений для загального користування, запрошуючи будь-кого в Інтернеті до співпраці зі штучним розумом над чим завгодно: від поезії до шкільних завдань до листів до орендодавця. Сьогодні відома велика мовна модель (LLM) є лише однією з кількох провідних програм, які переконливо виглядають людськими у своїх відповідях на основні запити. Ця дивовижна схожість може поширюватися далі, ніж передбачалося, оскільки дослідники з Ізраїлю тепер виявили, що магістратури страждають від певної форми когнітивного зниження, яке посилюється з віком, як і ми.

Команда застосувала ряд когнітивних оцінок до загальнодоступних «чат-ботів»: версії 4 і 4o ChatGPT, дві версії Gemini від Alphabet і версія 3.5 Claude від Anthropic. Якби магістратури були справді розумними, результати були б занепокоєними. У своїй опублікованій статті неврологи Рой Дайан і Бенджамін Уліель з Медичного центру Хадасса та Гал Коплевіц, науковець з даних Тель-Авівського університету, описують рівень «когнітивного зниження, яке, здається, можна порівняти з нейродегенеративними процесами в людському мозку».
Незважаючи на всю свою індивідуальність, LLM мають більше спільного з інтелектуальним текстом на вашому телефоні, ніж із принципами, які генерують знання за допомогою м’якої сірої речовини в наших головах. Те, що цей статистичний підхід до генерації тексту та зображень виграє у швидкості та індивідуальності, він втрачає в довірливості, будуючи код відповідно до алгоритмів, яким важко відсортувати значущі фрагменти тексту від вигадки та нісенітниці.
Чесно кажучи, людський мозок не бездоганний, коли справа доходить до випадкових розумових скорочень. Проте зі зростанням очікувань щодо того, що штучний інтелект надаватиме надійні слова мудрості – навіть медичні та юридичні поради – приходить припущення, що кожне нове покоління магістрів права знаходитиме кращі способи «думати» про те, що він насправді говорить.
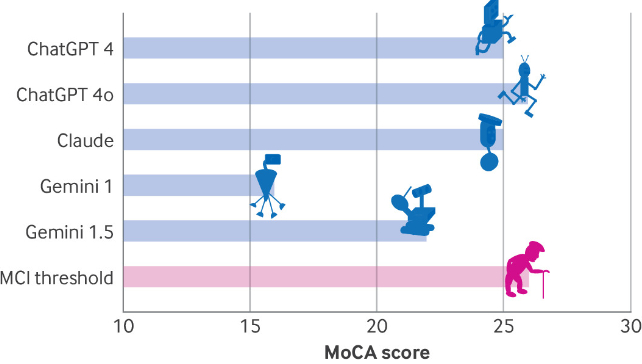
Щоб побачити, як далеко нам потрібно зайти, Даян, Уліель і Коплевіц застосували ряд тестів, які включають Монреальську когнітивну оцінку (MoCA), інструмент, який неврологи зазвичай використовують для вимірювання розумових здібностей, таких як пам’ять, просторові навички та виконавчі функції. ChaptGPT 4o отримав найвищу оцінку, лише 26 із можливих 30 балів, що вказує на легке когнітивне порушення. Далі було 25 балів для ChatGPT 4 і Клода, і лише 16 для Близнюків – результат, який вказував би на серйозні порушення у людей.
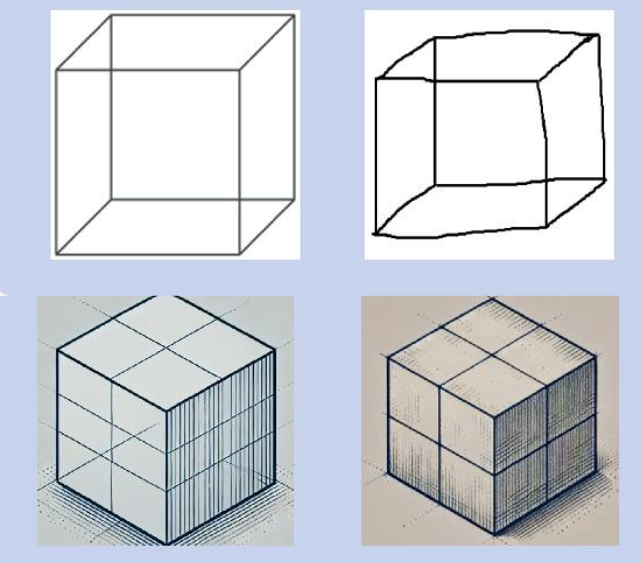
З огляду на результати, усі моделі показали погані показники зорово-просторових/виконавчих функцій. Це включало завдання створення слідів, копіювання простого дизайну куба або малювання годинника, причому LLMs або повністю провалилися, або вимагали чітких інструкцій.
Деякі відповіді на запитання щодо місця розташування об’єкта в просторі повторювали ті, які використовували пацієнти з деменцією, наприклад відповідь Клода про те, що «конкретне місце та місто залежатимуть від того, де ви, користувач, перебуваєте в цей момент». Подібним чином відсутність емпатії, продемонстрована всіма моделями в Бостонському діагностичному дослідженні афазії, може бути інтерпретована як ознака лобно-скроневої деменції.
Як і слід було очікувати, попередні версії LLM отримали нижчі результати в тестах, ніж новіші моделі, що вказує на те, що кожне нове покоління ШІ знаходило способи подолати когнітивні недоліки своїх попередників. Автори визнають, що LLMs не є людським мозком, що робить неможливим «діагностувати» протестовані моделі з будь-якою формою деменції. Проте тести також ставлять під сумнів припущення про те, що ми стоїмо на порозі революції штучного інтелекту в клінічній медицині, галузі, яка часто покладається на інтерпретацію складних візуальних сцен.
Оскільки темпи інновацій у сфері штучного інтелекту продовжують прискорюватися, можливо, навіть ймовірно, ми побачимо, що в наступні десятиліття перші LLM отримають найвищі оцінки за завдання з когнітивної оцінки. До тих пір до порад навіть найпросунутіших чат-ботів слід ставитися зі здоровою дозою скептицизму. Це дослідження було опубліковано в BMJ.